Triton-TLE 新语言赋能 MoE 算子优化: 实现对比CUDA最高 4.06 倍性能提升!
编者按:
针对 MoE 推理的性能瓶颈,众智 FlagOS 基于 Triton 语言扩展 TLE(Triton Language Extensions) 设计并实现两套针对性优化方案,目前已全量集成至 FlagTree 编译器中,开发者安装 FlagTree 后即可直接调用 TLE 接口编写高性能 MoE 算子:
-
triton_atomic_fused 方案:面向大 token 场景优化,通过单 kernel 全流程融合彻底解决单 block 串行瓶颈,实测相对 SGLang CUDA 实现最大 4.06 倍性能提升;
-
tle_cluster_fused 方案:聚焦小 token 低延迟需求,延迟表现显著优于 SGLang 方案,且相较各类 Triton 原生实现均实现数倍性能提升。
作为一种 Python DSL 形式的算子编程语言,Triton 基于 Block 的编程理念屏蔽了复杂硬件细节,并通过编译器优化实现高性能算子。这些优点吸引了大量开发者围绕 Triton 形成庞大的社区生态。随着 DSA 和新兴 GPU 芯片架构的出现,Triton 对硬件的适配进展缓慢。另外,相较于新兴语言 Gluon、Tilelang 等,Triton 在细粒度控制存储层和并行粒度上缺少抽象,性能劣势逐步显现。针对 Triton 发展的困境,众智 FlagOS 社区提出了全新语言 TLE(Triton Language Extentions),从三个层级扩展 Triton 能力,满足开发者在算子开发上的不同需求。Triton-TLE 突破了传统 Triton 只能在性能与开发效率间权衡的局限,实现了高性能、高开发效率与多硬件适配的多维兼顾。
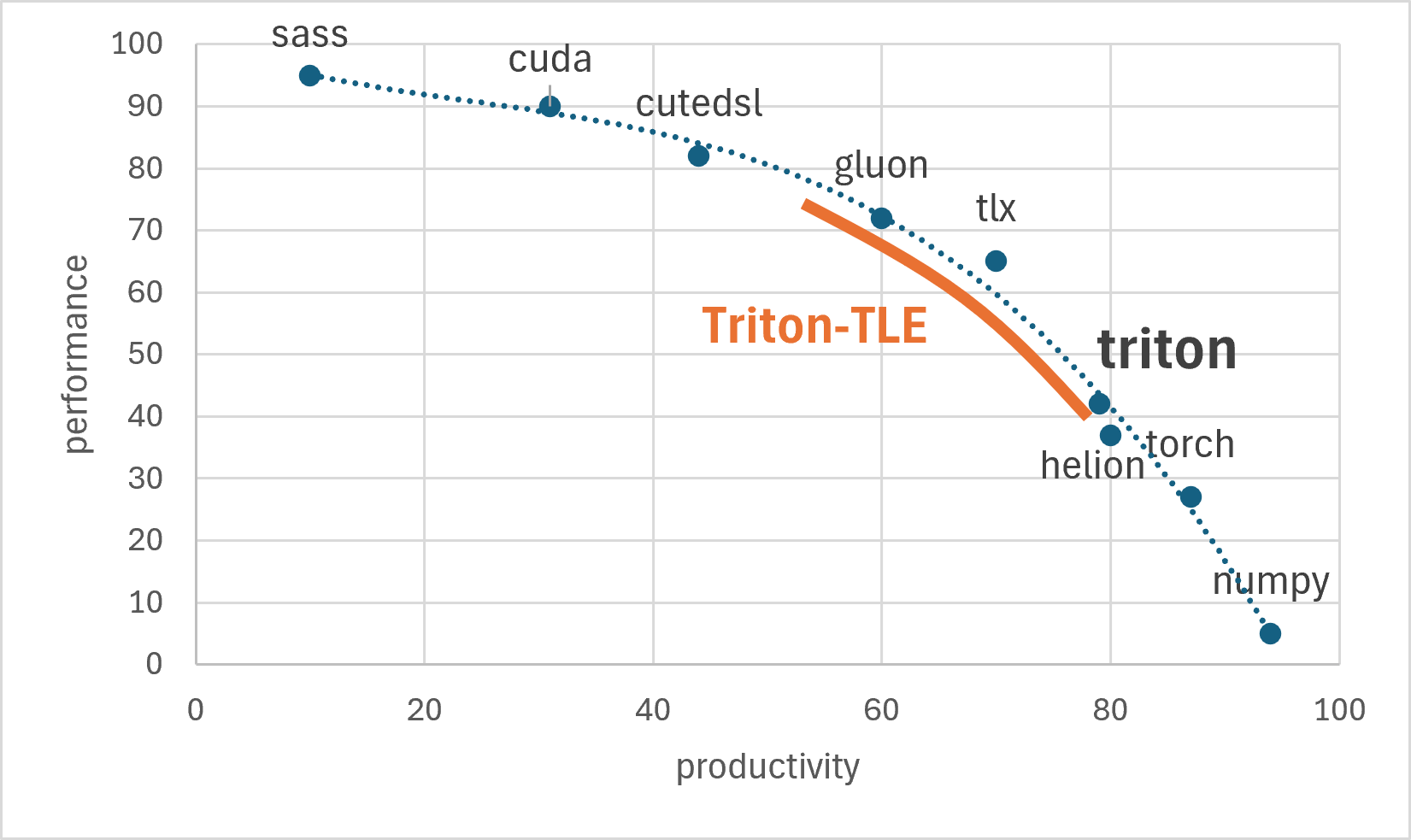
针对 MoE 模型中关键算子 MoE Align Block Size 的优化方案,本文将对比 TLE、SGLang、yiakwy、原生 Triton 的实现方式,并通过核心功能解读、优化原理剖析和芯片硬件实测验证,完整展现 TLE 在 MoE 推理关键算子优化上的性能优势。通过实测验证,TLE 在关键算子 MoE Align Block Size 优化上,相比 SGLang_CUDA 等传统方案性能最高提升 4.06倍!
01 为什么要优化 MoE Align Block Size 算子?
MoE(混合专家模型)凭借“稀疏激活、按需调用”的特性,成为大模型兼顾参数规模与推理效率的主流架构,但大规模 MoE 推理的性能瓶颈往往并非核心计算环节,而是卡在数据规整、对齐、分桶等前置阶段。MoE Align Block Size 正是这一阶段性能敏感、开销占比高、且极易成为全链路瓶颈的关键算子。
MoE Align Block Size 算子主要解决两件事。其一,基于路由结果(topk_ids)完成海量 token 按所属 expert 进行分桶;其二,将各 expert 对应的 token 段长度补齐至 block_size 整数倍,为后续 GEMM/GroupGEMM 高效计算提供规整输入。该算子是MoE模型中一个关键的预处理算子。
然而,当 token 规模(num_token)与专家数量(num_experts)同步扩增,且 expert 访问分布呈现典型长尾特征时,计数、前缀和对齐、scatter 重排、padding 补齐等核心环节的并行度不足或内存访问模式劣化问题会被放大;传统实现中存在的单 block 串行瓶颈、多阶段 kernel 启动开销、全局内存高频读写、跨 block 同步成本过高等缺陷,会直接导致算子性能断崖式下降,进而拖累整个 MoE 推理链路的端到端性能。
针对这些痛点,业界现有三类主流实现方案,但都存在明显短板。我们先从 CUDA 生态的两条典型路线看起,其一是 SGLang 方案的核心结构与单 block 瓶颈,其二是基于 cooperative grid 将多阶段合并为一次启动的改进方案,第三种是 Triton 生态下的 FlagGems 实现。
02 MoE Align Block Size 算子传统优化方案的分析
2.1 SGLang CUDA 实现的单 block 瓶颈问题
首先聚焦 SGLang 的核心 kernel 结构及其性能瓶颈,其最核心的问题是单 block 串行逻辑成为大规模场景的性能死结,即便通过多种优化手段调整,仍无法适配十万级 token 与数百专家的大规模 MoE 推理需求。
其结构如下:
第一次 kernel 启动:moe_align_block_size_kernel<<<2, 1024, shared_mem>>>
-
blockIdx.x==0负责计数、对齐前缀和、填写expert_ids,并写入cumsum_buffer -
blockIdx.x==1负责填充sorted_token_ids中的 sentinel(可选,但通常需要确定性输出)
第二次 kernel 启动:count_and_sort_expert_tokens_kernel<<<many blocks>>>
-
rank_post_pad = atomicAdd(&cumsum_buffer[topk_id+1], 1) -
sorted_token_ids[rank_post_pad] = token_id
关键约定:
-
dummy slot 0:scatter 中使用
topk_id+1,因此 host 侧的num_experts与cumsum_buffer需要预留 dummy slot;padding 方式也会影响输出的确定性和校验口径。
其核心缺陷在于:虽然 scatter kernel 可以扩展到多个 block,但计数、对齐前缀和、填写 expert_ids 这些步骤仍集中在单个 block 内,且需要遍历所有 token。随着 num_tokens 增大,这部分工作很容易成为主要耗时。
关键点总结
值得注意的是,SGLang 虽尝试通过向量化 padding、并行化前缀和、减少 __syncthreads()等思路优化性能,但均未触及这一核心瓶颈。
2.2 yiakwy CUDA 使用的协同启动机制仍存在中间内存开销问题
yiakwy CUDA 针对 SGLang 单 block 瓶颈进行改进,采用 cooperative launch 方案,将计数、前缀和、对齐、scatter 等多阶段流程整合到一次 kernel 启动中,通过 grid.sync() 实现阶段间同步,有效避免了单 block 串行与多 kernel 启动带来的性能损耗。
其核心流程如下:
- 每个 block 执行 shared histogram:按 token 切分,每个 block 在 shared memory 中统计各自负责的 token,得到 per-expert 计数。
- 物化 per-block counts 并归约:将每个 block 的计数写入
tokens_cnts_buffer,然后进行跨 block 归约,得到每个 expert 的全局计数。 - 对齐与全局前缀和:对全局计数按
block_size对齐并执行 scan,得到每个 expert 的起始偏移(写入cumsum_buffer),同时填写expert_ids。 - scatter 写
sorted_token_ids:再次遍历 tokens,使用atomicAdd(&cumsum[expert], 1)获取写入位置,并写出 token id(此阶段cumsum同时作为计数器使用)。
此外,该实现存在明确的使用约束,且本文的 benchmark 测试也十分受限:
- 代码中硬编码了
MAX_NUM_EXPERTS 256,并假设num_experts <= 256(许多 shared memory 布局和并行分工依赖此限制)。 - 输入
topk_ids在实现中被视为二维张量[num_tokens, K](K 为 top-k 路由数);对于 Top-1 场景可以兼容(K=1),但未对top-1场景进行特殊优化。 - 该实现使用了CUDA的协同启动机制,但 GPU 对协同启动的 block 总数有限制(不同型号上限不同,如某些卡可能限制为 32 或 64)。当
num_blocks过大时,kernel启动时会报too many blocks in cooperative launch(不同 GPU 的上限不同)。 - 为了规避上述约束导致的benchmark失败,本文的 benchmark 仅在
num_experts <= 256时尝试运行该实现;若 cooperative 启动失败,则记为na。
尽管 yiakwy CUDA 通过协同启动提升了并行度,但其核心缺陷仍未解决:流程中仍需物化 tokens_cnts_buffer 中间计数矩阵,并基于全局内存完成跨 block 归约与数据聚合;scatter 阶段也仍以全局内存计数器为核心分配写入位置。这种设计导致全局中间缓冲的频繁读写产生显著带宽开销,并未从根本上消除中间存储带来的资源占用与数据搬运成本。
2.3 FlagGems Triton 实现的多阶段开销问题
FlagGems 是面向训练与推理场景的算子与 kernel 集合,其典型实现路径为 “PyTorch 封装层 + Triton 内核”,兼具易用性与可维护性。本文选取其中使用原生Triton语言实现的 moe_align_block_size 算子作为性能基线,考虑该实现结构清晰、各阶段边界明确,便于后续针对性收敛每一环的性能瓶颈。
FlagGems 采用典型的 4 阶段拆分:
- Stage1:Histogram(计数) :每个 program 统计一段 token,将结果写入
tokens_cnts_ptr[(pid+1), :] - Stage2:对
tokens_cnts按列扫描 :对每个 expert 做列方向的 cumsum,得到每个 program 的prefix_before - Stage3:对齐与 expert 维度 cumsum :从最后一行获取总计数,进行对齐和 expert 维度的 cumsum,得到起始偏移量
- Stage4:scatter :填写
expert_ids,并以tokens_cnts作为计数器,scatter 写入sorted_token_ids
上述四阶段流程的核心性能损耗源于全局内存中的 tokens_cnts 中间矩阵:该矩阵形状为 (num_experts+1, num_experts),以 num_experts=512、num_programs=512 为例,其内存占用约为 513×512×4B ≈ 1.0 MiB。看似占用量不大,但该矩阵在 Stage1(写入计数)、Stage2(列扫描读取/写入)、Stage4(计数器读取)中被高频读写;叠加四次独立 kernel 启动的调度开销、输出数组初始化的内存带宽消耗,整体内存相关开销在大规模场景下被急剧放大,成为性能拖慢的关键因素。
FlagGems 的性能瓶颈集中体现在两个层面,且无法通过 Triton 原生能力解决。一是原子操作冲突:在未引入 TLE 扩展的情况下,Stage1 中多个 program 向全局内存 tokens_cnts_ptr 写入计数时,会触发严重的原子操作竞争,导致计数环节的执行效率大幅下降;二是多阶段固有开销:即便为 Stage1 增加 shared histogram 优化(将局部计数先写入共享内存再合并),仍无法规避 tokens_cnts 矩阵的高频带宽消耗,且四次独立 kernel 启动带来的调度延迟、阶段间同步成本,会随着 num_tokens 和 num_experts 的增长持续累积,最终导致整体性能难以适配大规模 MoE 推理场景。
2.4 Triton Atomic 融合单阶段的过渡优化方案
针对 FlagGems 基准实现暴露的核心问题——tokens_cnts 这类中间状态不仅占用大量全局内存带宽,还因多阶段拆分引入额外的 kernel 启动开销,本文首先提出一种过渡性优化方案:Triton Atomic。该方案未对全流程进行彻底重构,而是利用原子操作的返回值特性,将 FlagGems 四阶段架构中的 Stage2(列扫描阶段)直接折叠,作为后续全流程融合优化的前置过渡版本。
具体执行逻辑:对每个 program 统计的 local_counts[e](e 为 expert 索引),执行 prefix_before[e] = atomicAdd(global_cumsum[e], local_counts[e])。该操作返回值为原子加前 global_cumsum[e] 的原始值,与原 Stage2 列扫描得到的 prefix_before 数值完全等价。
该方案存在显著权衡代价:一是需执行 num_programs * num_experts 次全局内存原子写操作,竞争冲突引入额外开销;二是虽省去 Stage2 列扫描,但仍需一次全局同步衔接“rank0 节点的对齐扫描流程”与“scatter 写入阶段”,未根除多阶段同步成本。
基于 SGLang 单 block 串行的并行度桎梏、yiakwy CUDA 协同启动仍存的全局内存开销、FlagGems 多阶段拆分导致的带宽与同步损耗,以及 Triton Atomic 未能根除的原子冲突与同步成本这四大现有路径瓶颈,FlagTree 针对性推出 Triton 语言扩展 TLE,从底层语言能力层面实现突破性优化。
03 TLE 语言的核心能力与优化方案
TLE(Triton Language Extensions)是 FlagTree 对 Triton 语言提供的扩展能力,针对不同专业度开发者采用三层渐进式架构设计。
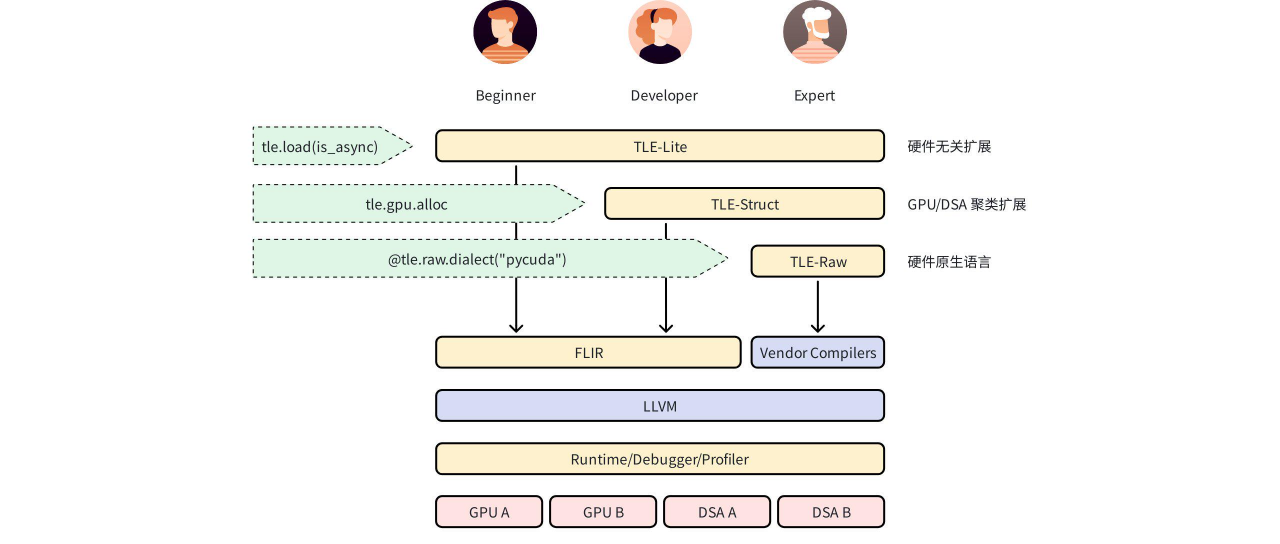
TLE-Lite 是对 Triton 的轻量级扩展,所有特性兼容各类硬件后端,仅需对原有 Triton kernels 少量修改即可拿到大幅性能提升。主要面向算法工程师和快速性能优化场景。
TLE-Struct 按硬件的架构聚类抽象,分类(如 GPGPU、DSA)提供扩展,满足进一步性能优化的需求。需要开发人员对目标硬件的特性和优化技巧有一定了解。
TLE-Raw 提供对硬件最直接的控制,可以使用硬件厂商的原生编程语言获取最极致的性能。需要开发人员对目标硬件的深入了解,主要面向性能优化专家。
其中 TLE-Lite 和 TLE-Struct 会通过 FLIR 最终 Lowering 到 LLVM IR,而 TLE-Raw 则通过语言对应的编译管线(如厂商的私有编译器)Lowering 到 LLVM IR。最后它们会被 Link 到一起,共同生成一个完整的 kernel 供 Runtime 加载和执行。
本文重点介绍TLE-Lite,其能力之一是解决传统 Triton 缺乏显式共享内存控制与跨 block、跨 cluster 分布式同步的核心短板。它通过提供显式共享内存视图与可组合分布式同步域两大关键能力,支持将多阶段流程合并为单次 kernel 启动,并把中间计算状态从高延迟的全局内存迁移至靠近计算核心的高速存储,显著降低内存带宽占用与多阶段同步开销,为 MoE 类复杂算子提供更强的性能优化支撑。
本文仅用到 TLE-Lite 的两类能力:
-
1. shared-memory 编程:
tle.alloc+tle.local_ptr -
2. 域内同步与分布式视图(这里用到的tled是tle的分布式原语):
-
tled.device_mesh+tled.distributed_barrier(mesh 覆盖 blocks 时对应 grid sync;覆盖 cluster shards 时对应 cluster sync) -
tled.shard_id(在 cluster mesh 内获取 shard/rank) -
tled.remote(构造 remote DSMEM/shared 的视图,用于 cluster 内跨 shard 读写)
-
基于 TLE,我们设计了 atomic_fused 与 tle_cluster_fused 两种针对性优化方案。下文将分别进行介绍。
3.1 atomic_fused 为大 token 场景最优方案
在高性能计算和 GPU 内核优化中,atomic fused 会把多个原子操作融合到单个内核(kernel)中,以减少内存访问开销和内核启动延迟。
实现见 https://github.com/flagos-ai/FlagTree/blob/triton_v3.5.x/python/tutorials/tle/02-moe_align_block_size.py 的 moe_align_block_size_triton_atomic_fused_coop。
该方案通过 cooperative grid 将多阶段流程融合为单 kernel,核心流程如下:
-
Stage0:初始化输出,将
cumsum_ptr清零,执行distributed_barrier。 -
Stage1:每个 program 在 shared memory 中做 histogram,然后通过
prefix_before = atomic_add(cumsum_ptr, local_counts)获得前缀偏移,并将prefix_before写回 shared 计数器,再次执行distributed_barrier。 -
Stage2:仅
pid==0的 program 负责对齐总计数并做 exclusive-scan,得到expert_starts,写入num_tokens_post_pad,然后执行distributed_barrier。 -
Stage3:填写
expert_ids。 -
Stage4:第二次扫描 token,利用 shared 计数器(初始值为
prefix_before)得到rank_in_prog,并写入sorted_token_ids[expert_starts + rank_in_prog]。
TLE 关键代码聚焦 grid 同步与共享内存原子操作:
mesh = tled.device_mesh({"block": [("block_x", NUM_BLOCKS)]})
if tl.program_id(0) == 0:
tl.store(cumsum_ptr + tl.arange(0, BLOCK_EXPERT), 0)
tled.distributed_barrier(mesh)
local_counts = tle.alloc([BLOCK_EXPERT], dtype=tl.int32, scope=tle.smem)
e = tl.arange(0, BLOCK_EXPERT)
ptrs = tle.local_ptr(local_counts, (e,))
tl.store(ptrs, 0)
local_counts_vals = tl.load(ptrs)
prefix_before = tl.atomic_add(cumsum_ptr + e, local_counts_vals)
其创新点在于:通过原子操作直接构造前缀偏移,省去独立扫描阶段;移除中间计数矩阵,节省相关带宽开销;单 kernel 内多阶段同步通过 TLE 分布式屏障实现,避免多次 kernel 启动成本。
与yiakwy CUDA相比,其共性与差异点如下:
-
1. 共性:均依赖 cooperative launch,在单次 kernel 内通过多次同步串联阶段;
-
2. 差异:yiakwy 物化
tokens_cnts_buffer并执行跨 block 归约,scatter 阶段依赖全局内存计数器;Atomic Fused 仅保留全局cumsum_ptr(兼具计数与起始偏移功能)和共享计数器,规避tokens_cnts物化,同步逻辑由mesh+barrier实现。
这里的“物化”特指为某类数据(如
tokens_cnts)分配实际的全局内存(GMEM)缓冲区 并持久化存储其值;而 TLE 版本中tokens_cnts仅存储在每个 block 的共享内存(SMEM)中,不占用 GMEM,属于 “非物化” 状态。
参数选择上,NUM_BLOCKS 需满足 NUM_BLOCKS <= ceil_div(num_tokens, BLOCK_TOKENS),且以 SM_count * cap_mult 为上限;若 cooperative 启动失败,则逐级减半 NUM_BLOCKS 直至启动成功。
3.2 tle_cluster_fused 为小 token 场景高效方案
atomic_fused 将并行度交由 cooperative grid 管理,更适合大 token 的吞吐场景。TLE 还提供了 cluster/DSMEM 路线:将执行域缩小到 SM90 的 cluster,把关键中间状态保留在 DSMEM 中,通过 remote 访问和 cluster 域同步完成聚合与 scatter。
moe_align_block_size_tle_cluster_fused 正是利用 SM90 cluster/DSMEM,将关键中间状态留在 cluster 内部,借助 remote 访问与 cluster 域同步,在单个 kernel 内完成统计、对齐与 scatter。
其核心流程如下:
- 每个 shard 在 shared memory 中做 histogram,然后将计数通过向量化的
atomic_add累加到 rank0 的 DSMEMcumsum中,得到本 shard 的prefix_before。 - rank0 对齐总计数并进行 scan,得到
expert_start_offsets与num_tokens_post_pad。 - 各 shard 第二次扫描 token,执行 scatter 并填写
expert_ids。
TLE原语:
该路线依赖三个关键点:cluster 维度的 mesh、cluster 域同步、以及 DSMEM remote 访问。代码形态大致如下:
mesh = tled.device_mesh({"block_cluster": [("cluster_x", 8)]})
cluster_rank = tled.shard_id(mesh, "cluster_x")
tled.distributed_barrier(mesh)
# 访问 rank0 的 DSMEM 视图(remote shared)
rank0_view = tled.remote(cumsum_local, 0, scope=mesh)
rank0_ptrs = tle.local_ptr(rank0_view, (expert_offsets,))
prefix_before = tl.atomic_add(rank0_ptrs, local_counts_vals)
需要明确的是,cluster_fused 方案存在显著的约束与取舍:硬件层面,需依赖 SM90 及以上 GPU 架构,且后端需支持 cluster remote lowering 特性;规模层面,当前实现受限于 shared memory 向量长度和内存分配机制,要求 num_experts <= 1024;并行度层面,cluster 内的 shard 数量为固定值,整体并行度上限远低于 cooperative grid 路线,这使得该方案在小规模 token 输入场景下因内存交互开销低而性能占优,但在大 token 场景下易因并行度不足,导致计数、scatter 等环节的瓶颈被放大。
与 atomic_fused 方案相比,两者核心共性是均通过原子操作返回值构造 prefix_before,核心差异则体现在同步域与并行度管理:atomic_fused 基于 cooperative grid 实现 block 域内的同步,并行度弹性更高;而 cluster_fused 以 cluster 为核心执行域,依托 DSMEM 完成聚合与同步,并行度上限更低但小规模场景交互开销更小。
因此,该方案的优势在于 cluster 内低延迟通信,在小 token 场景下可避免大规模并行带来的调度开销,但受限于 cluster 并行度上限,更适合小规模输入场景。
04 Benchmark : 标准化的性能验证体系
为确保性能数据的可复现性与可解释性,本文先明确统一的 benchmark 测试口径与数据集,为各方案的性能对比建立客观基准。
4.1 测试方法
将所有待对比的实现版本整合至同一测试脚本中,采用 triton.testing.do_bench 工具测量各方案的 p50 单次执行耗时(剔除极端值,更贴近实际运行情况);同时严格对齐所有方案的输入输出语义,避免因逻辑差异导致性能对比失真。
本次对比覆盖 6 类核心实现:
-
triton:FlagGems 基准版本(四阶段拆分的原生 Triton 实现);
-
triton_atomic:原子操作前缀化优化版本(折叠列扫描阶段);
-
triton_atomic_fused:TLE cooperative 单 kernel 版本(自研);
-
tle_cluster_fused:TLE cluster/DSMEM 单 kernel 版本(自研);
-
sglang_cuda:SGLang CUDA 实现(单 block 串行核心逻辑);
-
yiakwy_cuda:yiakwy cooperative CUDA 实现(仅在
num_experts<=256时运行,超出则标注为 na)。
4.2 测试数据集
为兼顾场景通用性与真实业务贴合度,采用两类数据集:
- synthetic 数据集:按 Zipf 分布采样 expert 归属,模拟真实 MoE 模型中 expert 访问的长尾分布特征;
- real 数据集:基于 Qwen3 Next 一次实际推理路由的 topk_ids 快照(Top-1 路由策略,
num_tokens=163840),还原真实业务的 token 规模与路由分布。
05 性能实测结果
为验证优化效果,我们在 RTX 5060 Ti 与 H800 两款 GPU 上,进行测试。本文将通过结果表格与可视化图示,直观展示各方案在不同硬件(RTX 5060 Ti、H800)、不同数据集下的 p50 单次耗时(单位:毫秒,数值越小性能越优)。
说明:RTX 5060 Ti 数据来自本地测试环境(Torch 2.8.0 + CUDA 12.8);H800 数据来自同口径的线上日志输出。
当大模型在处理不同任务(通常以 token 计量大小)时,GPU 的工作状态或受限于计算利用率,或受限于显存带宽利用率。根据经验,token 规模小于 4096,我们称为小 token 规模任务;token 数量大于 4096,我们称为大 token 规模任务。
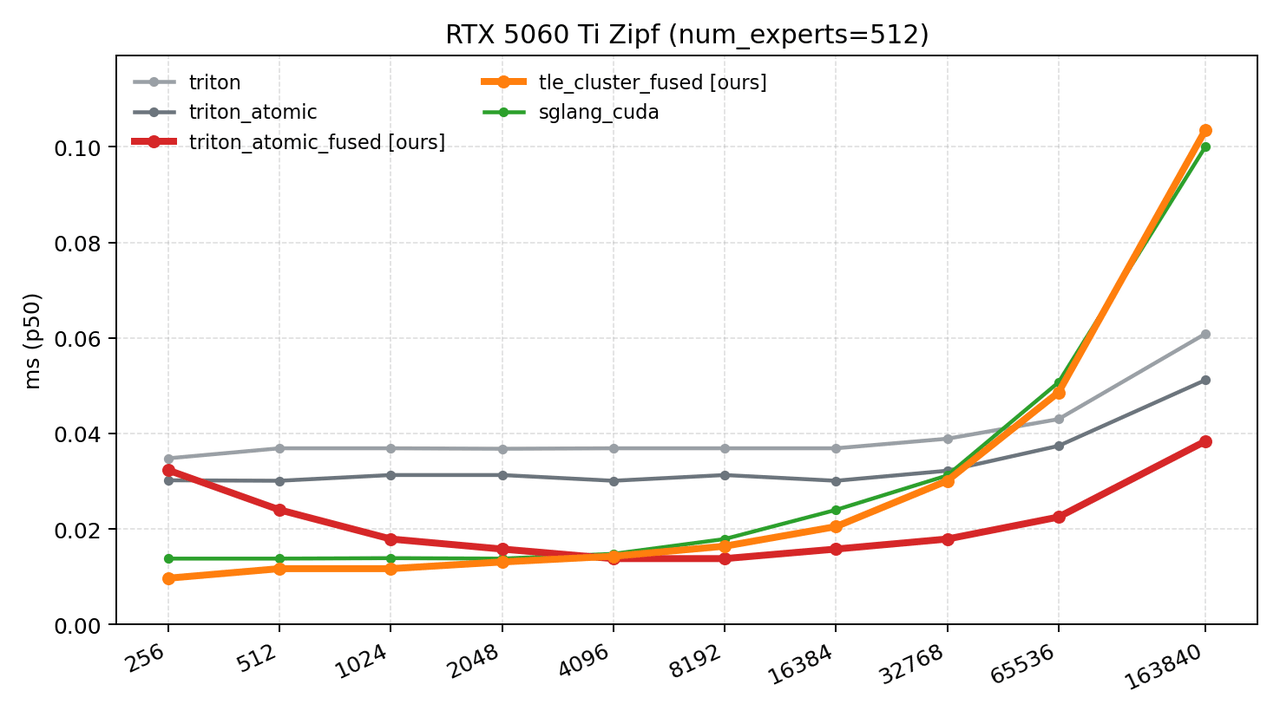
5.1 RTX 5060 Ti 测试结果
|
num_tokens |
triton(ms)
|
triton_atomic(ms) |
triton_atomic_fused(ms) [ours] |
tle_cluster_fused (ms)[ours] |
sglang_cuda(ms) |
|
256 |
0.0348 |
0.0302 |
0.0323 |
0.0097 |
0.0138 |
|
512 |
0.0369 |
0.0301 |
0.0240 |
0.0117 |
0.0138 |
|
1024 |
0.0369 |
0.0313 |
0.0179 |
0.0117 |
0.0139 |
|
2048 |
0.0368 |
0.0313 |
0.0158 |
0.0131 |
0.0138 |
|
4096 |
0.0369 |
0.0301 |
0.0138 |
0.0143 |
0.0148 |
|
8192 |
0.0369 |
0.0313 |
0.0138 |
0.0164 |
0.0179 |
|
16384 |
0.0369 |
0.0301 |
0.0158 |
0.0205 |
0.0240 |
|
32768 |
0.0389 |
0.0322 |
0.0179 |
0.0301 |
0.0312 |
|
65536 |
0.0430 |
0.0374 |
0.0225 |
0.0486 |
0.0507 |
|
163840 |
0.0609 |
0.0512 |
0.0384 |
0.1036 |
0.1001 |
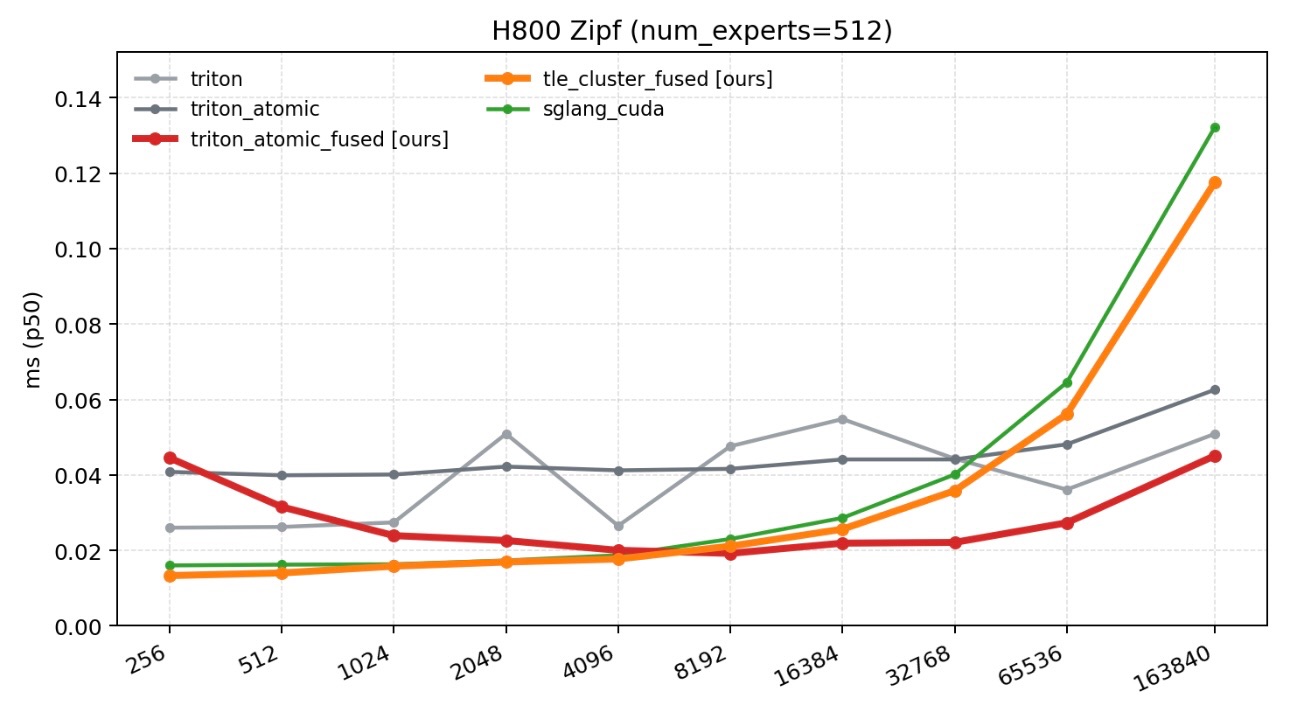
5.2 H800测试结果
|
num_tokens |
triton |
triton_atomic
|
triton_atomic_fused [ours] |
tle_cluster_fused [ours] |
sglang_cuda |
|
256 |
0.026 |
0.0408 |
0.0445 |
0.0133 |
0.016 |
|
512 |
0.0262 |
0.0399 |
0.0315 |
0.014 |
0.0162 |
|
1024 |
0.0274 |
0.0401 |
0.0239 |
0.0158 |
0.0163 |
|
2048 |
0.0509 |
0.0422 |
0.0226 |
0.0169 |
0.0173 |
|
4096 |
0.0265 |
0.0412 |
0.02 |
0.0177 |
0.0187 |
|
8192 |
0.0476 |
0.0416 |
0.0192 |
0.0211 |
0.0230 |
|
16384 |
0.0548 |
0.0441 |
0.0219 |
0.0256 |
0.0286 |
|
32768 |
0.0443 |
0.0441 |
0.0221 |
0.0358 |
0.0401 |
|
65536 |
0.0361 |
0.0481 |
0.0273 |
0.0561 |
0.0645 |
|
163840 |
0.0509 |
0.0626 |
0.0451 |
0.1177 |
0.1323 |
5.3 实际业务场景测试结果
在num_tokens=163840, num_experts=512, block_size=16情况下:
|
hardware |
RTX 5060 |
H800 latency(ms) |
|
triton |
0.0512 |
0.0397 |
|
triton_atomic |
0.0384 |
0.0497 |
|
triton_atomic_fused [ours] |
0.0261
|
0.0358
|
|
tle_cluster_fused [ours] |
0.0537 |
0.0604 |
|
sglang_cuda |
0.1060 |
0.1412 |
根据结果表格与可视化图示可知:
- 小 token 规模任务场景:tle_cluster_fused 更占优:在小token场景下,整体计算量轻、数据量小,kernel启动开销与内存访问效率成为性能主导因素。原生Triton因多阶段拆分时延最高;TLE 的 atomic_fused 优化方案通过单 kernel 融合消除启动开销,表现稳定;而 tle_cluster_fused 依托 SM90 DSMEM 近存与轻量同步,内存路径最短,在小token、低时延场景下性能最优。传统 CUDA 方案受串行拖累,整体表现弱于 TLE 系列优化。
- 大 token 规模任务场景:atomic_fused 方案表现最优:通过并行化计数与单 kernel 多阶段融合,彻底解决了 SGLang 单 block 瓶颈,在真实数据集中实现最高近 4 倍性能提升。通过 TLE 语言的核心能力,大幅降低了中间内存开销与同步成本,相比传统实现具有更强的场景适应性。
说明:性能加速比计算方式为
sglang_cuda / triton_atomic_fused = 0.1060 / 0.0261 ≈ 4.06x
06 总结
本文通过分析 MoE Align Block Size 算子的核心瓶颈,提出了基于 Triton-TLE 新语言的两类优化方案。关键结论如下。
- 传统实现的核心痛点在于并行度不足、中间内存开销大与同步成本高,TLE 语言通过补充分布式同步与共享内存管理能力,为解决这些问题提供了关键技术支撑;
- atomic_fused 方案通过单 kernel 多阶段融合与并行化计数,在大 token 真实场景中实现最高 4.06 倍性能提升,成为大规模 MoE 推理的最优解;
- tle_cluster_fused 方案针对小 token 场景优化,借助 cluster 级高效通信实现 1.2-1.42 倍性能提升,丰富了方案的场景适应性。
未来,众智 FlagOS 团队将继续基于 Triton-TLE 语言扩展,探索更多 MoE 相关算子的优化空间,为大模型训练与推理提供更高效的底层支撑。
参考文章及代码:
- SGLang kernel 源码:https://raw.githubusercontent.com/sgl-project/sglang/refs/heads/main/sgl-kernel/csrc/moe/moe_align_kernel.cu
- 优化过程解析(BBuf):sgl-kernel MoE Align Block Size Kernel 优化过程解析https://zhuanlan.zhihu.com/p/1974251309587780175
- 参考文章(yiakwy-xpu-team):https://huggingface.tw/blog/yiakwy-xpu-team/efficient-moe-align-sort-design-for-sglang
- 参考实现(CUDA 源码):https://raw.githubusercontent.com/yiakwy-xpu-ml-framework-team/AMD-sglang-benchmark-fork/d9831e330bd312fc00557187834d0f5b12ea5c70/sgl-kernel/src/sgl-kernel/csrc/moe_align_kernel.cu
点击链接,了解更多TLE :https://github.com/flagos-ai/FlagTree/tree/triton_v3.5.x

欢迎来到FlagOS开发社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐



 1
1 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)