cuda知识
或者dpkg -l | grep cudnn。查看tensorrt版本:dpkg -l | grep TensorRT。查看cuda版本:`nvcc` --version,nvcc -V。
查看版本
#查看cuda版本
nvcc --version,nvcc -V
#或者
cat /usr/local/cuda/version.txt
#查看cudnn版本:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
#或者
dpkg -l | grep cudnn
#查看tensorrt版本
dpkg -l | grep TensorRT
#查看驱动版本:
cat /proc/driver/nvidia/versionnvidia-smi看不到进程,但是显存有被占用
#这个命令就能看到pid了,如果kill不掉的话再看下面
nvidia-smi --query-compute-apps=pid,used_memory --format=csv
#将下面命令的pid再删除就可以了
fuser -v /dev/nvidia* #或者lsof -v /dev/nvidia*,看具体的卡就nvidia6
显卡锁频
nvidia-smi -pm 1 # 开启persistance模式
nvidia-smi -q -d CLOCK #查看每张显卡的最大SM时钟频率(Max Clocks)和当前时钟频率(Clocks)
# nvidia-smi -pl 125 # set power limit to 125W
nvidia-smi -lgc 500,500 # 锁定gpu clock, 两个数字分别是minGpuClock,
nvidia-smi -rgc #恢复到不锁频的状态在使用ncu profile程序时,要加上--clock-control=none来阻止ncu控制gpu频率。
nvidia-smi
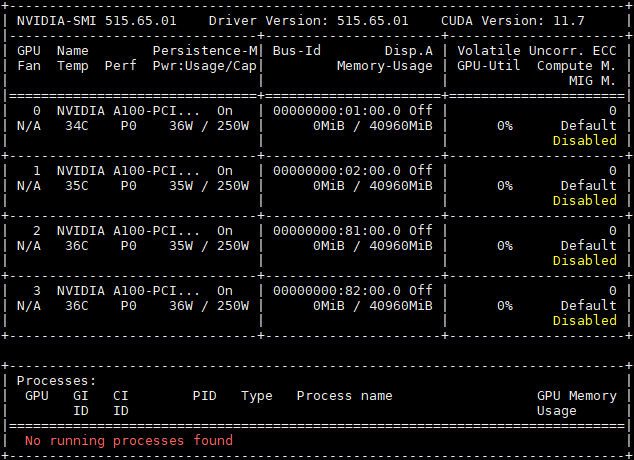
nvidia-smi常见功能
|
指标 |
含义 |
配置方式 |
|---|---|---|
|
Fan |
N/A是风扇转速,从0到100%之间变动,这个速度是计算机期望的风扇转速,实际情况下如果风扇堵转,可能达不到显示的转速。有的设备不会返回转速,因为它不依赖风扇冷却而是通过其他外设保持低温。 |
参考调节风扇转速调节风扇转速。 |
|
Temp |
温度,单位摄氏度。 |
无法调节。 |
|
Perf |
性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。 |
无法调节。 |
|
Pwr |
代表能耗,代表GPU的实时能耗和最大能耗。 |
无法调节。 |
|
Persistence-M |
是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是on的状态。 建议开启GPU的持久模式。GPU默认持久模式关闭的时候,GPU如果负载低,会休眠。之后唤起的时候,有一定几率失败。 |
执行以下命令开启持久模式。 nvidia-smi -pm 1 |
|
Bus-Id |
GPU总线ID,依次代表domain:bus:device.function。 |
无法调节。 |
|
Disp.A |
Display Active,表示GPU的显示是否初始化。 |
无法调节。 |
|
Memory Usage |
代表显存使用率。 |
无法调节。 |
|
GPU Util |
代表浮动的GPU利用率,对应流处理器的利用率。 |
无法调节。 |
|
ECC |
实现“错误检查和纠正”的技术。 |
|
|
Compute M |
代表计算模式。 |
切换计算应用模式。 nvidia-smi -c 0/1/2 其中:0代表DEFAULT,1代表EXCLUSIVE_PROCESS,2代表PROHIBITED。 |
最下面区域表示每个进程占用的显存使用率。还有一些指标无法从图形中得出,但是对性能的影响比较大。
- 工作频率设置:nvidia-smi -ac 1215,1410,设定<memory,graphics>时钟为最大。
- 锁频设置:nvidia-smi -lgc 1410,1410,设定<minGpuClock,maxGpuClock>时钟为最大。
- nvidia-smi -q |grep -i vbios确保所有GPU的固件版本一致,否则可能影响性能。

为了实时查看GPU的详细信息,可以使用nvidia-smi dmon命令。
GPU统计信息以一行的滚动格式显示,要监控的指标可以基于终端窗口的宽度进行调整。 监控最多4个GPU,如果没有指定任何GPU,则默认监控GPU0-GPU3(GPU索引从0开始)。
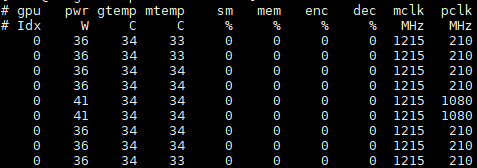
nvidia-smi dmon附加选项
|
命令 |
功能 |
|---|---|
|
nvidia-smi dmon -i xxx |
用逗号分隔GPU索引,PCI总线ID或UUID。 |
|
nvidia-smi dmon -d xxx |
指定刷新时间(默认为1秒)。 |
|
nvidia-smi dmon -c xxx |
显示指定数目的统计信息并退出。 |
|
nvidia-smi dmon -s xxx |
指定显示哪些监控指标(默认为puc),其中:
|
|
nvidia-smi dmon -o D/T |
指定显示的时间格式D:YYYYMMDD,T:HH:MM:SS。 |
|
nvidia-smi dmon -f xxx |
将查询的信息输出到具体的文件中,不在终端显示。 |
很多情况下设备监控可参考的价值不高,这时就要监控GPU进程,监控命令nvidia-smi pmon,以滚动条形式显示GPU进程状态信息。
|
命令 |
功能 |
|---|---|
|
nvidia-smi pmon -i xxx |
用逗号分隔GPU索引,PCI总线ID或UUID。 |
|
nvidia-smi pmon -d xxx |
指定刷新时间(默认为1秒)。 |
|
nvidia-smi pmon -c xxx |
显示指定数目的统计信息并退出。 |
|
nvidia-smi pmon -s xxx |
指定显示哪些监控指标(默认为u),其中:
|
|
nvidia-smi pmon -o D/T |
指定显示的时间格式D:YYYYMMDD,T:HH:MM:SS。 |
|
nvidia-smi pmon -f xxx |
将查询的信息输出到具体的文件中,不在终端显示。 |
查看显卡是否加装nvlink
nvidia-smi nvlink --status下面的图表示0-3卡加装了nvlink,4-7卡没有加装。
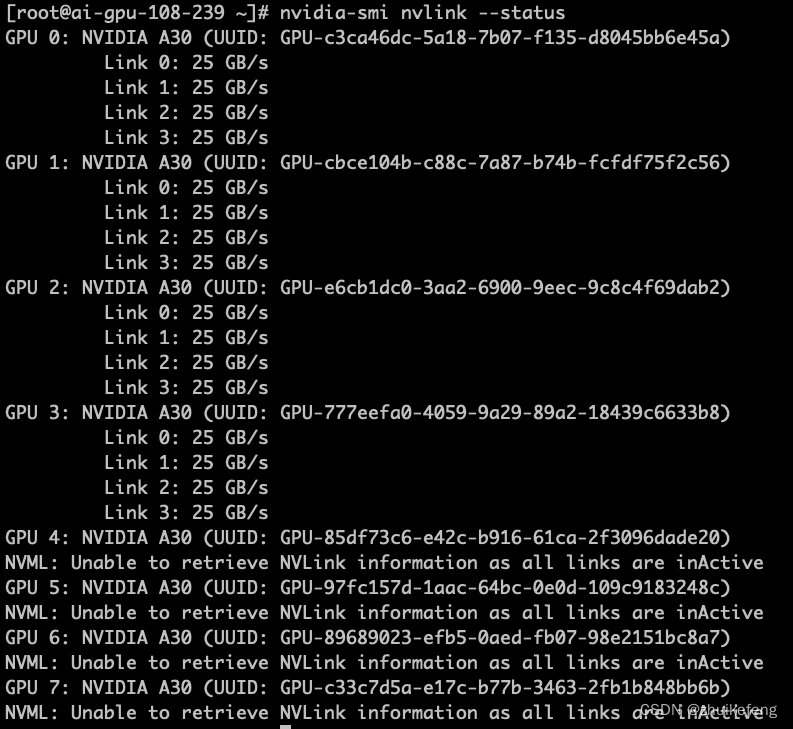
NVLink和NVSwitch的关系
NVLink 是一种 GPU 之间的直接互连,可扩展服务器内的多 GPU 输入/输出 (IO)。
NVSwitch 可连接多个 NVLink,在单节点内和节点间实现以 NVLink 能够达到的最高速度进行多对多 GPU 通信。
简单来说,NVLink是GPU两两连接,NVSwitch是多卡连接,比如一台服务器的8张卡。
L20,L40S,A30
| 显卡型号 | H20 | L20 | A800 | A100 | A30 |
| 架构 | Hopper | Ada Lovelace | Ampere | Ampere | Ampere |
| FP32 | 44TFLOPS | 59.8 TFLOPS | 19.5 TFLOPS | 19.5 TFLOPS | 10.3 |
| FP16 | 148TFLOPS | 119.5 TFLOPS | 312 TFLOPS | 312 TFLOPS | 165 |
| FP8 | 296TFLOPS | 239 TFLOPS | no | no | no |
| INT8 | 296TFLOPS | 239 TFLOPS | 624 TFLOPS | 624 TFLOPS | 330 |
| 显存带宽 | 4TB/s | 864GB/s | 1935GB/s | 1935GB/s | 933GB/s |
| 显存大小 | 96GB HBM3 | 48GB GDDR6 | 80GB HBM2e | 80GB HBM2e | 24GB HBM2 |
安装指定版本的nvcc
#安装nvcc
apt install nvidia-cuda-toolkit
#查看nvcc版本
nvcc -V
#安装指定版本nvcc
apt search cuda-toolkit
apt install cuda-toolkit-12-1
#报错The following packages have unmet dependencies:
# cuda-libraries-12-1 : Depends: libcublas-12-1 (>= 12.1.3.1) but 12.1.0.26-1 is to #be installed
# libcublas-dev-12-1 : Depends: libcublas-12-1 (>= 12.1.3.1) but 12.1.0.26-1 is to #be installed
apt update
apt -y upgrade #更新软件包
apt-mark showhold #有一些包被系统“hold”,也就是阻止它们自动升级,那么需要解除hold状态
apt-mark unhold <package-name>
apt update
apt -y upgrade
apt install cuda-toolkit-12-1显卡拓扑结构
下面是一台 8*A800 机器上 nvidia-smi 显示的实际拓扑(网卡两两做了 bond,NIC 0~3 都是 bond):
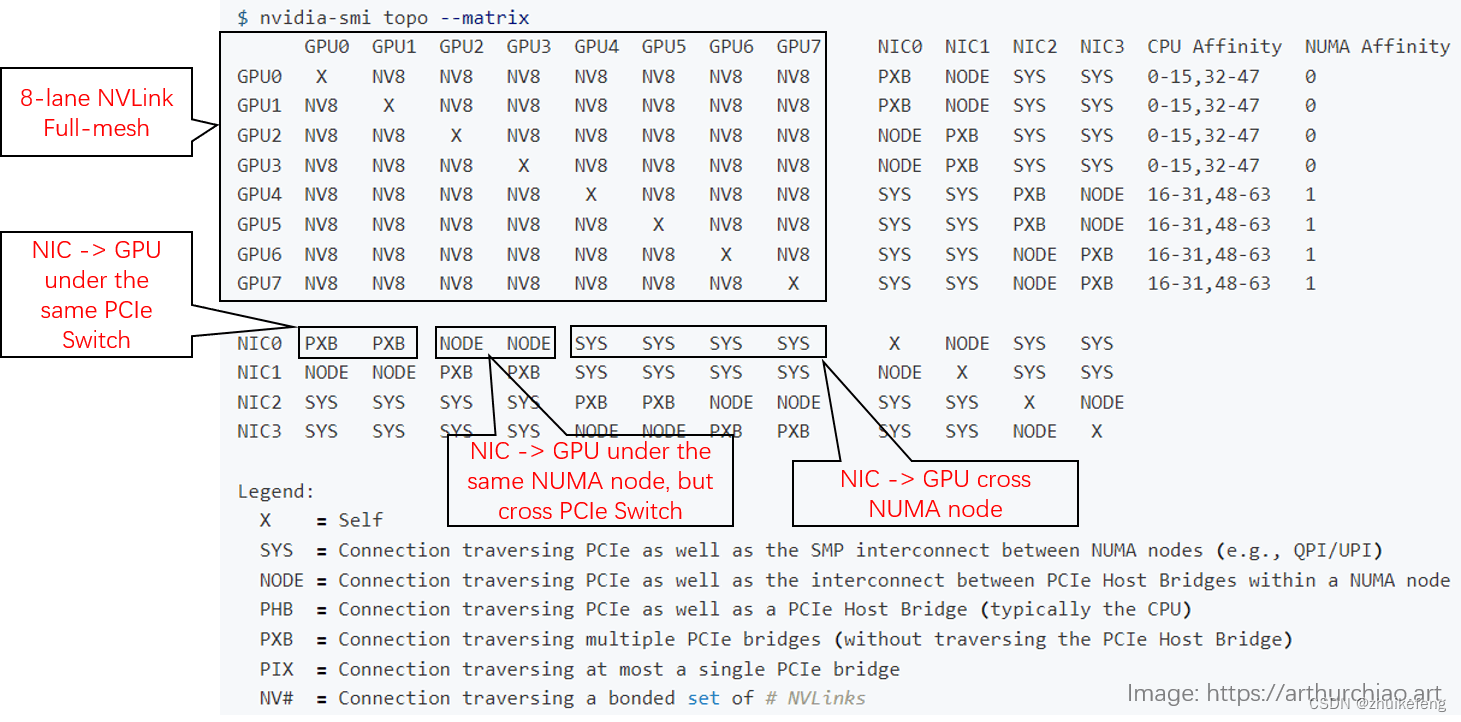
- GPU 之间(左上角区域):都是
NV8,表示 8 条 NVLink 连接; -
NIC 之间:
- 在同一片 CPU 上:
NODE,表示不需要跨 NUMA,但需要跨 PCIe 交换芯片; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA;
- 在同一片 CPU 上:
-
GPU 和 NIC 之间:
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
PXB,表示只需要跨 PCIe 交换芯片; - 在同一片 CPU 上,且不在同一个 PCIe Switch 芯片下面:
NODE,表示需要跨 PCIe 交换芯片和 PCIe Host Bridge; - 不在同一片 CPU 上:
SYS,表示需要跨 NUMA、PCIe 交换芯片,距离最远;
- 在同一片 CPU 上,且在同一个 PCIe Switch 芯片下面:
显卡拓扑中SYS和PIX的含义
在nvidia-smi topo --matrix命令中,输出的矩阵描述了GPU之间的通信拓扑结构以及它们之间的连接类型。这里提到的SYS和PIX代表了两种不同的连接方式,具体解释如下:
-
SYS (System Interconnect) :这种连接类型表示数据传输不仅穿过PCI Express (PCIe)总线,还可能跨越了NUMA节点间的系统级互连。NUMA(Non-Uniform Memory Access)架构是指多处理器系统中,CPU访问不同内存区域的速度不同,通常本地内存(与CPU同属一个节点的内存)访问速度快于非本地内存。QPI (Quick Path Interconnect) 和 UPI (Ultra Path Interconnect) 是Intel处理器用于NUMA节点间高速通信的技术实例。因此,当显示为SYS时,意味着通信路径可能包括了PCIe和如QPI/UPI这样的高速互连,这通常意味着相对较高的延迟或更低的带宽与直接的PCIe连接相比。
-
PIX (PCIe Interconnect) :这表示数据传输仅通过一个PCI Express桥接器。换句话说,这是指GPU之间通过最短的PCIe路径相连,没有涉及到更复杂的系统级互连如NUMA节点间的QPI或UPI。这种连接通常提供较低的延迟和更高的带宽,因为数据不需要经过额外的系统层级的转发或处理,是GPU间通信较为直接和高效的方式。
SYS跨越NUMA(Non-Uniform Memory Access)节点间的通信之所以可能导致速度变慢,主要是因为NUMA架构的设计特点和系统内存访问的非一致性。
在NUMA架构中,每个CPU或CPU核心都紧密地连接到自己的本地内存,这种内存访问速度非常快。当CPU需要访问属于另一个NUMA节点的内存时,就需要通过较慢的系统互联(如QPI、UPI或其他类型的互联)来完成,这个过程比访问本地内存要慢得多,原因如下:
-
增加了延迟:跨NUMA节点访问内存需要通过系统互连,这引入了额外的信号传输时间和协议处理时间,导致访问延迟增加。
-
降低了带宽:虽然系统互连提供了CPU间通信的能力,但其带宽通常低于CPU直接访问本地内存的带宽。这意味着大量数据传输时速度会受限。
-
内存争用和拥塞:当多个CPU试图通过共享的系统互连访问内存时,可能会遇到资源争用问题,进一步降低效率。
-
缓存一致性问题:跨NUMA节点的内存访问可能会影响缓存一致性协议的效率,因为需要确保所有CPU看到的数据是一致的,这可能引入额外的管理和同步开销。
因此,在设计需要高性能和低延迟的应用程序时,通常建议尽量优化数据布局和任务分配,以减少跨NUMA节点的内存访问,或者利用软件手段(如NUMA感知的分配策略)和硬件配置(如调整NUMA策略)来优化NUMA系统的性能。在某些场景下,如果发现SYS级别的通信成为瓶颈,关闭NUMA功能或调整NUMA配置可能会有所帮助。

欢迎来到FlagOS开发社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)