使用triton部署OCR服务(一)
NVIDIA Triton Inference Server 是一个开源软件,专为简化和加速在生产环境中部署深度学习模型的过程而设计。它支持多种深度学习框架(如 TensorFlow、PyTorch、ONNX 等)的模型,并能够在 GPU、CPU 以及 AWS、GCP 和 Azure 上提供的各种硬件平台上运行。主要功能多框架支持:支持包括 TensorFlow、PyTorch、ONNX、Open
文章目录
0. Triton Inference Server简介
NVIDIA Triton Inference Server 是一个开源软件,专为简化和加速在生产环境中部署深度学习模型的过程而设计。
它支持多种深度学习框架(如 TensorFlow、PyTorch、ONNX 等)的模型,并能够在 GPU、CPU 以及 AWS、GCP 和 Azure 上提供的各种硬件平台上运行。
主要功能
- 多框架支持:支持包括 TensorFlow、PyTorch、ONNX、OpenVINO 等在内的多种深度学习框架。
- 动态批处理:自动将多个推理请求组合成更大的批次,以提高GPU利用率和整体吞吐量。
- 并发模型执行:允许同时运行多个模型或同一模型的多个实例,以便优化资源使用并减少延迟。
- 模型版本管理:支持模型的版本控制和热更新,使得可以在不中断服务的情况下更新模型。
- 远程模型部署:通过HTTP/REST、gRPC等协议提供接口,便于远程调用和集成。
解决的痛点
- 部署复杂性:在没有Triton之前,将深度学习模型部署到生产环境中通常需要大量的定制代码来处理加载、预处理、后处理和优化等问题。Triton大大简化了这一流程。
- 性能瓶颈:特别是在高并发请求下,如何高效利用硬件资源(特别是昂贵的GPU资源)是一个挑战。Triton通过其先进的批处理和并发执行策略有效解决了这个问题。
- 跨平台兼容性问题:支持多种框架和硬件平台,使得跨平台部署变得更加容易,减少了针对不同平台重复开发的工作量。
NVIDIA Triton Inference Server 旨在为开发者提供一个强大的工具,使其能够更方便地将复杂的深度学习模型快速部署到生产环境中,同时保证了高性能和良好的资源利用率。
OCR模型管道:
- 预处理
- 文本检测
- 裁剪文本区域
- 文本识别
部署的挑战:
- 不同的模型框架

- 各模型的队列、版本、缓存、加速等管理
拉取镜像 nvcr.io/nvidia/tritonserver:24.10-py3,并创建进入容器
克隆代码 git clone https://github.com/triton-inference-server/tutorials.git
进入 tutorials\Conceptual_Guide\Part_1-model_deployment
1. 文本检测模型
下载 tensorflow 模型
wget https://www.dropbox.com/s/r2ingd0l3zt8hxs/frozen_east_text_detection.tar.gz
tar -xvf frozen_east_text_detection.tar.gz
导出 onnx
pip install -U tf2onnx tensorflow
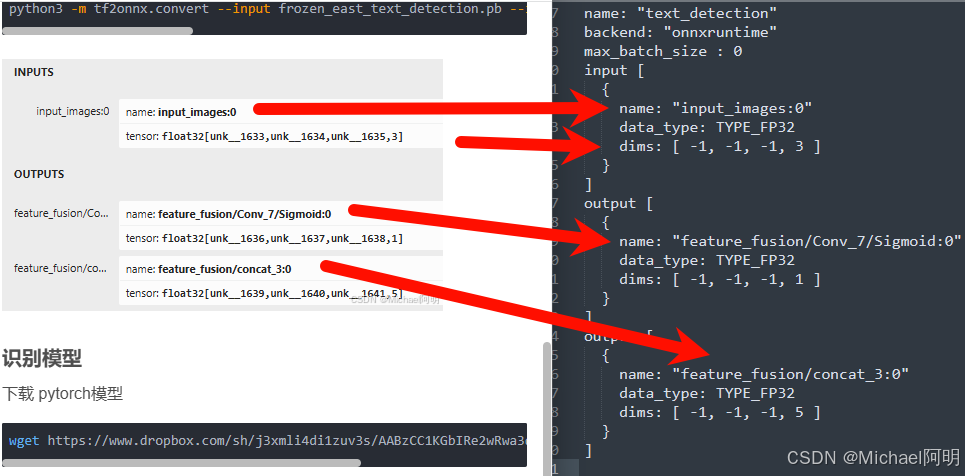
python3 -m tf2onnx.convert --input frozen_east_text_detection.pb --inputs "input_images:0" --outputs "feature_fusion/Conv_7/Sigmoid:0","feature_fusion/concat_3:0" --output detection.onnx
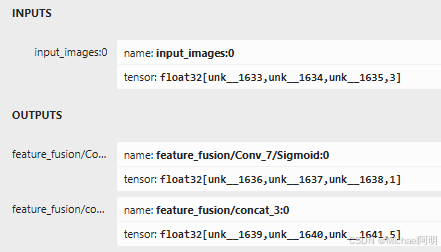
2. 识别模型
下载 pytorch模型
wget https://www.dropbox.com/sh/j3xmli4di1zuv3s/AABzCC1KGbIRe2wRwa3diWKwa/None-ResNet-None-CTC.pth
使用代码导出onnx模型
import torch
from utils.model import STRModel
# Create PyTorch Model Object
model = STRModel(input_channels=1, output_channels=512, num_classes=37)
# Load model weights from external file
state = torch.load("None-ResNet-None-CTC.pth")
state = {key.replace("module.", ""): value for key, value in state.items()}
model.load_state_dict(state)
# Create ONNX file by tracing model
trace_input = torch.randn(1, 1, 32, 100)
torch.onnx.export(model, trace_input, "str.onnx", verbose=True)
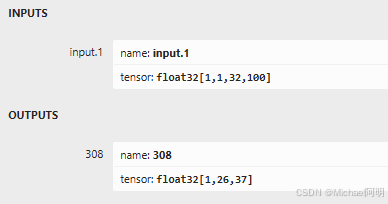
3. 设置模型存储库
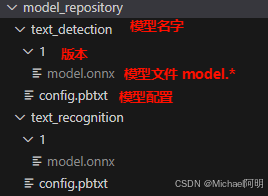
4. 模型配置
需要跟 可视化里面看到的一致,包含输入输出的name,数据类型、shape、模型名字跟文件夹名字一致,后端(onnxruntime、python、pytorch等)
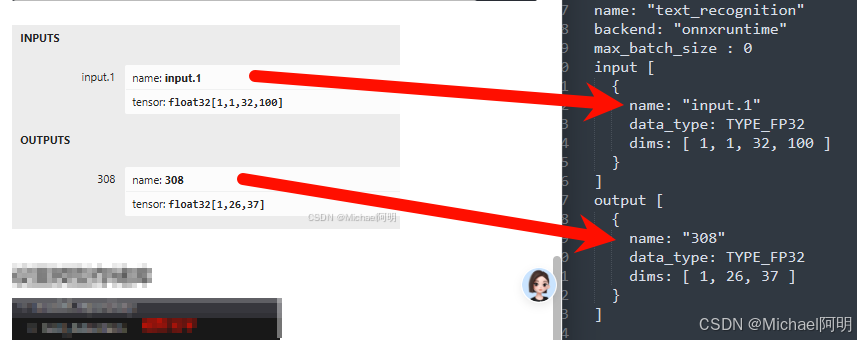
5. 启动服务器
tritonserver --model-repository=./model_repository/
可以看到两个模型 READY 了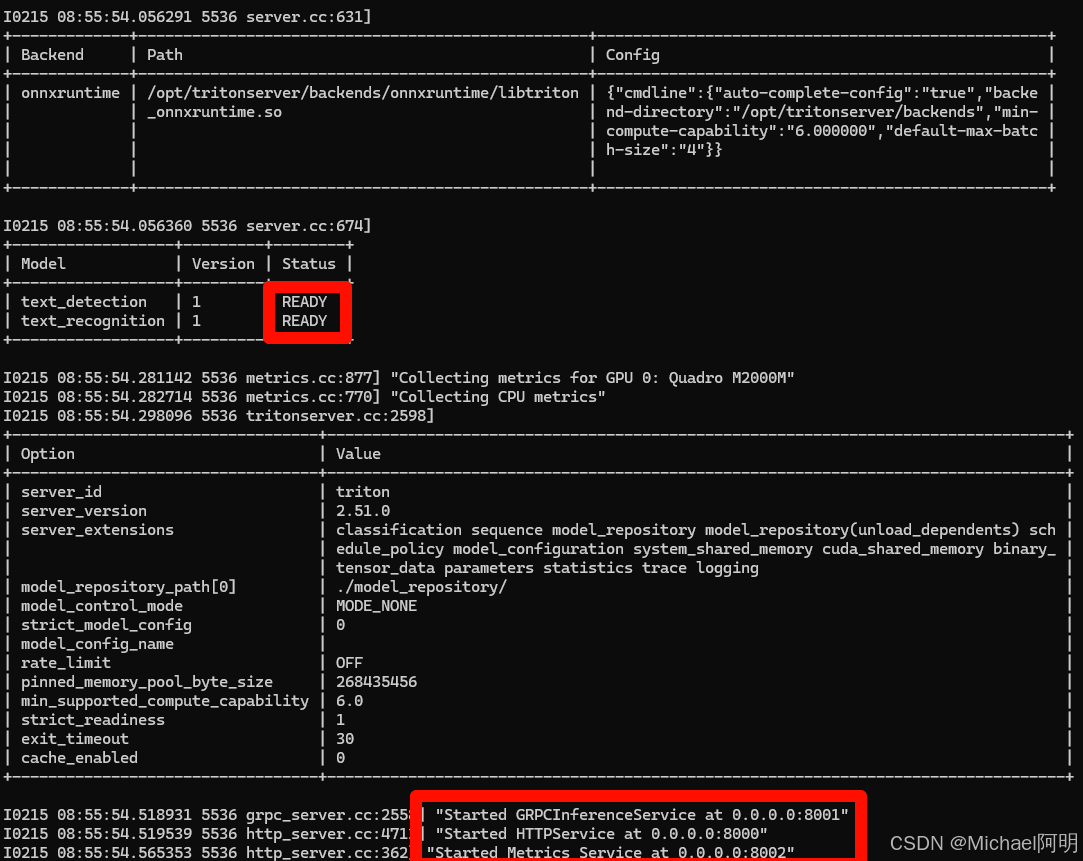
6. 客户端调用
有 http、grpc,c APIs 可以调用
pip install tritonclient[all]
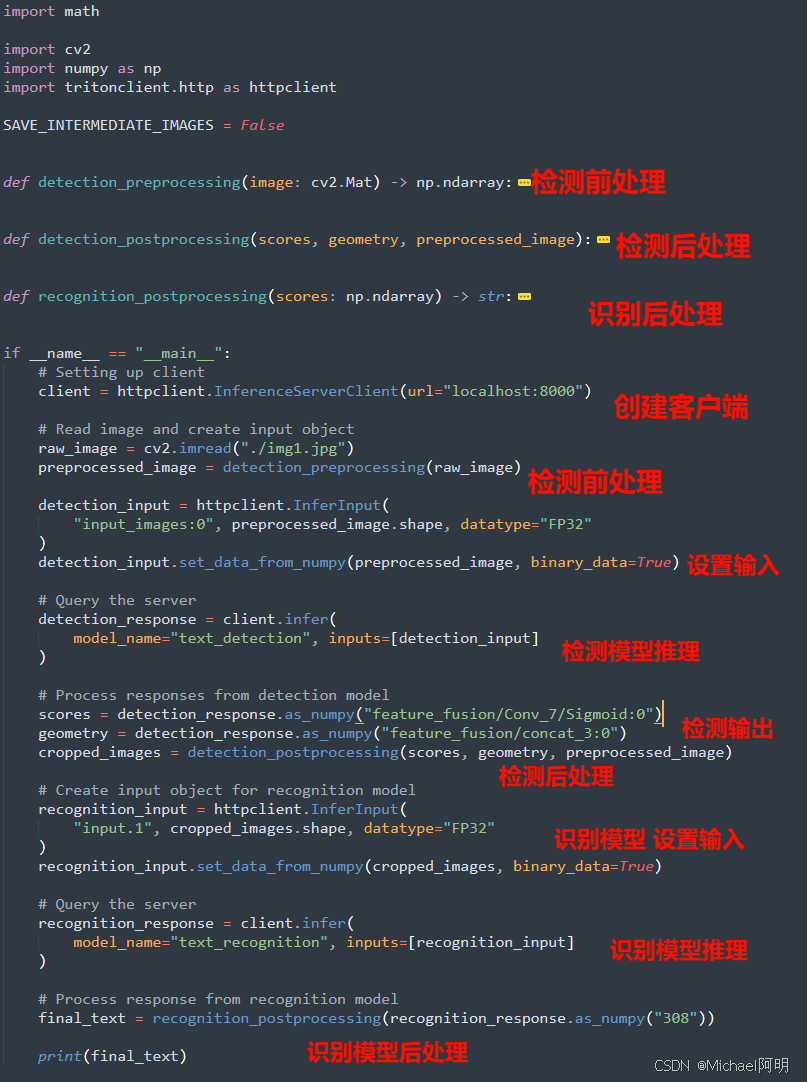
输入图片:
输出:
# python3 client.py
[ WARN:0@2.957] global loadsave.cpp:848 imwrite_ Unsupported depth image for selected encoder is fallbacked to CV_8U.
stop
7. 模型版本发布
目录下可以添加新的版本
默认是会使用最新的,可以设置策略
# 全部可用
version_policy: { all { }}
# 指定版本可用
version_policy: { specific: { versions: [1,3]}}
# 最新的 2 个模型可用
version_policy: { latest: { num_versions: 2}}
8. 模型加载卸载
tritonserver --model-repository=./model_repository/ --model-control-mode=poll
Triton Inference Server 的模型加载策略(NONE、EXPLICIT、POLL)决定了服务器如何管理模型的加载、卸载和更新。
-
Model Control Mode NONE:
- 在启动时尝试加载模型库中的所有模型。
- 运行时对模型库的更改将被忽略。
- 不接受模型加载和卸载请求。
-
Model Control Mode EXPLICIT:
- 仅加载通过
load选项显式指定的模型。 - 启动后,所有模型加载和卸载操作必须通过模型控制协议显式发起。
- 仅加载通过
启动后,服务中没有任何模型,需要自己手动启动
# text_detection 为模型名字
curl -X POST localhost:8000/v2/repository/models/text_detection/load
卸载 就把 load 改成 unload
如果有新版了,直接 load 就会加载新版本,不必卸载老版本,服务不中断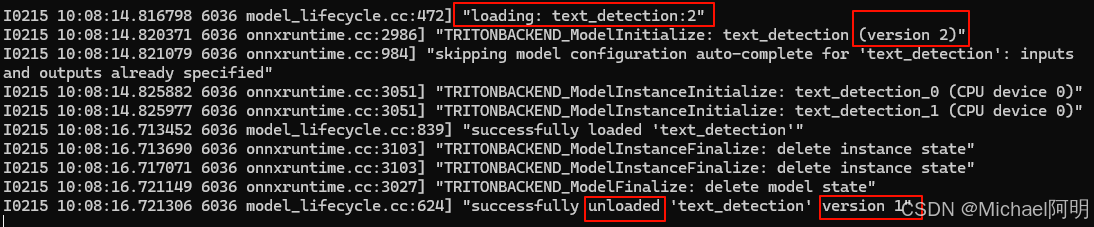
- Model Control Mode POLL:
- 在启动时尝试加载模型库中的所有模型。
- 通过定期轮询检测模型库的更改并加载或卸载模型。
- 轮询间隔可以通过
--repository-poll-secs选项控制。 - 不推荐在生产环境中使用,可能会检测到部分和不完整的更改。
- 持续交付:CI/CD 流水线中自动部署新模型。
- 开发/测试环境:频繁迭代模型版本时无需手动干预。

欢迎来到FlagOS开发社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)