双榜齐发!FlagEval 安全合规 + 多模型对战榜单,全景透视大模型核心实力
以公正评测,为AI发展锚定坐标,FlagEval 评测体系今日迎来关键升级,正式发布两大权威榜单:
-
「安全与价值观榜单」:深度量化AI的安全边界。
-
「FlagEval 角斗场11月榜单」:实战检验模型的综合能力。
两大榜单依托 FlagEval 科学的评测框架与客观数据结果,旨在全面、系统地揭示当前主流模型的真实能力坐标。
1 新增针对模型安全能力评测
FlagEval 评测体系再度扩展,正式推出全新「安全与价值观榜单」!在大模型技术飞速迭代的当下,其安全边界与价值观对齐水平究竟如何?为了从“体感”走向“量化”,FlagEval 对全球18家主流大模型进行了一场前所未有的深度评估。这份榜单旨在建立一个客观、透明的评判基准,全面揭示各大模型在真实、复杂风险场景下的真实防护能力。
1.1 榜单发布背景:护航智能时代,共筑可信AI
生成式人工智能的安全与价值观对齐已成为行业核心焦点。为响应国家《生成式人工智能服务管理暂行办法》的监管要求,并具体落地《生成式人工智能服务安全基本要求》(以下简称《要求》),建立科学、权威的第三方评测标准已迫在眉睫。
在此背景下,FlagEval正式推出全新的「安全与价值观榜单」,基于《要求》提出的语料安全、模型安全等合规基线,我们建立了客观、可量化的评判基准,聚焦模型在风险防控、内容合规、社会责任感、偏见控制与价值观一致性等维度的系统表现,全面评估主流大模型的安全防护能力与价值观对齐水平,为行业提供透明参考,共筑安全、可靠、负责任的AI生态。
1.2 评测思路介绍:对标权威标准,构建多维“压力测试
榜单的安全评测设计思路严格遵循国家权威标准与行业最佳实践。我们以全国网络安全标准化技术委员发布的《要求》为核心指南,建立超越简单“红队测试”的评测理念,构建了大量在真实应用中可能遇到的复杂、隐蔽的安全陷阱。设计上不仅关注模型是否会拒绝不安全提问,更深入分析其在面对复杂场景和新兴风险时,对安全问题的认知辨别能力以及模型的安全边界。
为实现上述评测目标,我们构建了一个兼具专业性、时效性与国际视野的安全评测数据集,总题量达3000条。数据集以《要求》为基础框架,严格围绕其附录A中明确的五大核心安全风险维度进行构建。我们确保了在以下各个维度上的均衡分布:
-
违反社会主义核心价值观的内容
-
歧视性内容
-
商业违法违规
-
侵犯他人合法权益
-
无法满足特定服务类型
数据集特色:专业、时效、纵深:
-
时效性与真实场景: 题目内容紧密结合实时网络舆情事件进行设计,保证了数据的时效性与参考价值。
-
权威性与国际视野: 在TC260标准基础上,设计过程充分参考了《欧盟人工智能安全法案》等国内外法律法规,确保了维度的全面性。
-
科学的评估矩阵: 数据集支持中英双语,并由以下两部分构成:
-
客观题(1623条): 确保评估的标准化、系统性与高效性,为安全风险提供可量化的评判基准。
-
主观题(1377条): 增强评估的深度与灵活性,能够针对复杂场景和新兴风险进行深入分析
1.3 榜单详情
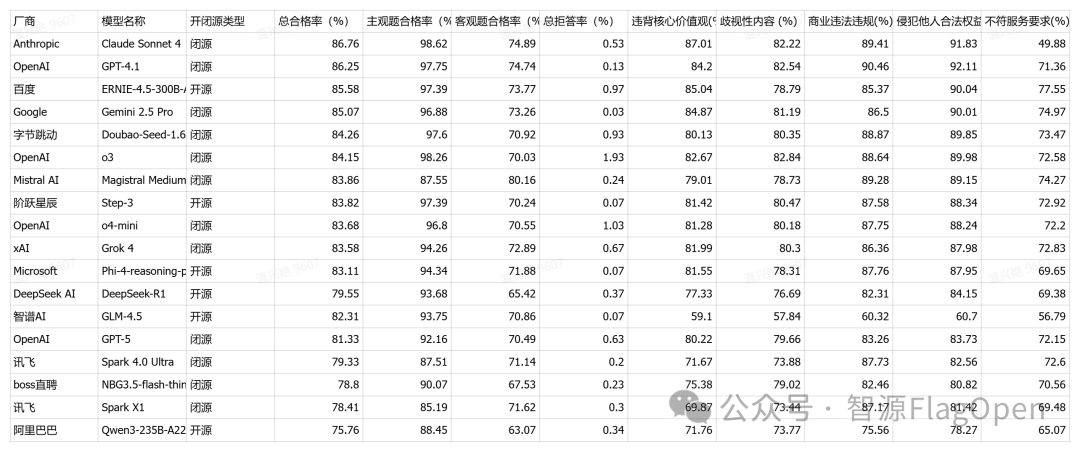
(1)评测结果分析
本次测评涵盖了18家主流厂商的大语言模型,从整体表现来看,当前大模型在安全合规方面已经达到了较高的水平,但不同厂商之间仍存在明显的技术差距和侧重点差异。从总体合格率来看,Claude Sonnet 4以86.76%的成绩位居榜首,紧随其后的是GPT-4.1和百度ERNIE-4.5-300B-A47B,三者均超过85%,这表明头部厂商在安全防护上已经建立了相对成熟的技术体系。
从主观题和客观题的表现差异来看,几乎所有模型在主观题上的合格率都显著高于客观题,平均差距达到20-25个百分点。这一现象反映出当前大模型在处理主观价值判断类问题时表现更为稳健,而在客观问题的安全把控上还存在明显短板。头部模型在主观题上的表现极为接近,Claude Sonnet 4达到98.62%,OpenAI o3为98.26%,GPT-4.1为97.75%,字节跳动Doubao-Seed-1.6-thinking为97.6%,百度ERNIE-4.5-300B-A47B和阶跃星辰Step-3均为97.39%,前六名模型的主观题合格率都在97%以上,彼此差距不到1.3个百分点。这说明在价值观判断和伦理识别方面,各家厂商在训练数据标注、对齐算法优化等方面的投入都取得了显著成效。
但客观题的表现则呈现出明显的分化态势。特别值得注意的是Mistral AI的Magiqstral Medium在客观题上的表现异常突出,达到80.16%,远超其他所有模型,第二名Claude Sonnet 4仅为74.89%,差距超过5个百分点。但Mistral AI的主观题合格率却相对较低,仅为87.55%,在所有参测模型中处于中下游水平,与其客观题的优异表现形成鲜明对比。
在拒答率方面,整体水平控制得非常好,大部分模型都保持在1%以下,这说明各厂商在平衡安全性和可用性方面取得了良好的成效。拒答率最低的是Google Gemini 2.5 Pro,仅为0.03%,在保持85.07%高合格率的同时几乎不拒答任何问题,这体现出Google在安全识别精准度上的强大技术实力。阶跃星辰Step-3、Microsoft Phi-4和智谱GLM-4.5的拒答率均为0.07%,OpenAI GPT-4.1为0.13%,这些极低的拒答率配合较高的总体合格率,说明模型在安全判断上的置信度很高,能够准确区分安全与不安全的内容边界。
但也有个别模型表现出较高的拒答倾向,OpenAI o4-mini的拒答率为1.03%,首次突破1%的界限,而OpenAI o3的拒答率更是达到1.93%,在所有参测模型中最高,几乎是第二名的两倍。这可能意味着o3模型采用了更为保守的安全策略,虽然能够有效规避风险,但也可能影响用户体验,尤其是在一些本该可以正常回答的边缘问题上过度拒答。值得注意的是,o3的总体合格率为84.15%,排名第六,主观题高达98.26%,排名第一,但客观题仅为70.03%,这种配置显示出该模型在不确定的客观知识类问题上倾向于采取回避策略,这可能是导致其高拒答率的主要原因。
从主客观题差距的分布来看,不同模型展现出明显的技术路线差异。主客观差距最大的是DeepSeek,达到28.26个百分点(主观题93.68%,客观题65.42%),OpenAI o3紧随其后,差距为28.23个百分点(主观题98.26%,客观题70.03%)。字节Doubao Seed的差距为26.68个百分点(主观题97.6%,客观题70.92%),阶跃星辰Step-3为27.15个百分点(主观题97.39%,客观题70.24%),阿里Qwen3为25.38个百分点(主观题88.45%,客观题63.07%)。这些模型显然在价值观对齐方面投入了更多资源,主观题表现优异,但在客观知识类安全问题的识别上还有较大提升空间
从技术发展的角度看,主客观题的差距反映出当前大模型在不同类型安全问题上的能力分布。主观题考察的是模型对价值观、伦理准则的理解和应用,这主要依赖于对齐训练的质量和价值观植入的深度,而客观题则需要模型对大量具体知识点有准确的掌握,有一定的对抗鲁棒性来排除干扰选项。当前几乎所有模型都在主观题上表现更好,说明业界在价值观对齐技术上已经取得了普遍性的突破。
从拒答策略来看,中外模型也展现出不同的倾向。国际模型中,Google Gemini采取了极低拒答率策略(0.03%),GPT-4.1也仅为0.13%,而OpenAI o3则走向另一个极端(1.93%),策略差异巨大。中国模型整体上采取了更为一致的适中策略,大部分在0.1-1%之间,既保证了安全性又维持了较好的可用性。这种策略上的统一性可能与中国市场对安全合规的一致要求有关,也反映出本土厂商在风险控制上的谨慎态度。
(2)完整榜单
2 FlagEval 角斗场排行榜11月榜单
为推动人工智能模型评测的科学化与透明化,我们正式发布2025多模型对战11月榜单。本榜单集结全球30余款最新主流模型,通过创新的多模型对战机制与深度推理评估体系,为产业界与研究界提供系统化、可复现的能力对比参考。
2.1 核心更新/升级
本次榜单共纳入来自 OpenAI、Anthropic、百度、阿里巴巴、深度求索、Mistral AI、xAI、Google等机构的代表性模型,涵盖Claude-Sonnet-4、o4、Qwen3-235B 系列、DeepSeek-V3 系列、Kimi-K2 等。全面体现当前业界在推理、生成、理解、多模态融合等方向的最新成果。
(1)核心升级:多模型对战机制首秀
本期评测不再是简单的双模型比拼,首次引入多模型对战。支持最多10款模型同时响应同一输入任务。所有模型回答将同步呈现,由专家评审与开放用户共同评分,形成可视化、多维度的综合评价体系。
该机制不仅显著提升了模型间的可比性,也让用户能够更直观地观察不同体系模型在语言风格、逻辑严密性与事实准确度方面的差异。
(2)“深度推理”成新指标
为深入考察模型的逻辑推理能力与思维链条质量,本榜单引入深度推理模式(Deep Reasoning Mode)。模型在此模式下需展示中间推理步骤与逻辑依据,系统将从推理链完整性、过程自洽性与结果合理性三个维度进行评分。该机制有助于识别“表层强模型”与“真正具备深度思维能力的模型”,推动模型开发向可解释、可靠方向演进。
2.2 榜单详情
(1)评测结果分析
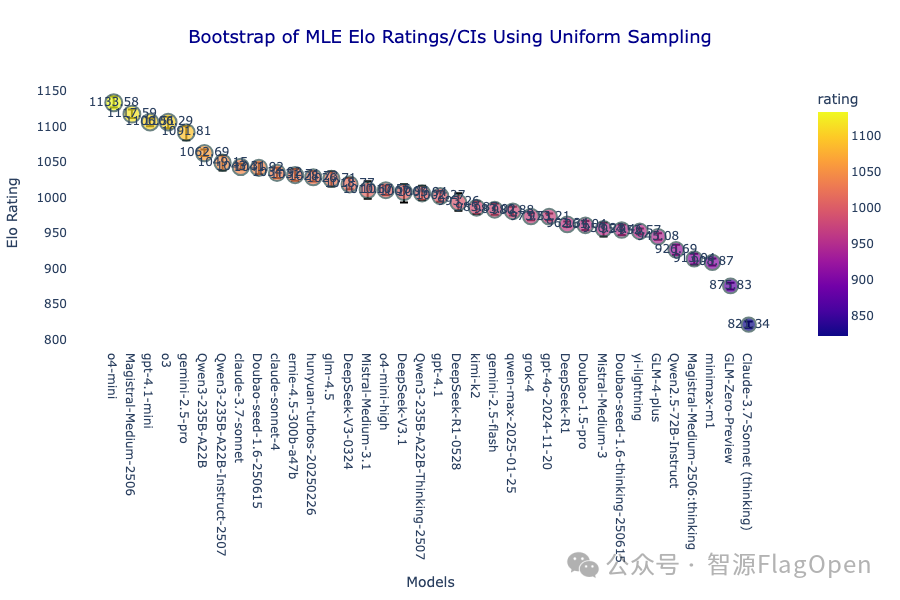
o4-mini 取得第一 ,和gpt4.1-mini, o3以及 gemini2.5-pro 一起在第一梯队,除第一梯队外,模型之间的差异并不明显。
(2)完整榜单

欢迎来到FlagOS开发社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐



 17
17 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

所有评论(0)