cuda_1
cuda学习记录
此帖为记录cuda学习笔记,可能有错误,恳请各位指出,谢谢。
如果用GPU解决我们的问题首先要把CPU上的数据复制到GPU上,通过PCIe或NVLink总线。
第二步就是实际执行 ,例如说运行cuda内核。这就是完成我们的计算任务了。
第三部就是计算完成后从GPU复制到CPU,通过网络或磁盘传输。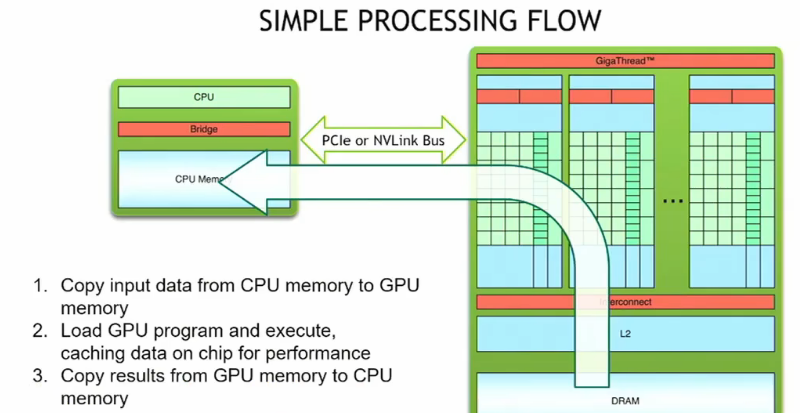
一些语法:
__global__ void mykernel(void){
}
为了让这段代码转换为可用的GPU代码,需要加一个装饰器,也就是__global__,__global__向编译器发出信号,表明这是一个需要编译的函数,以便它能在GPU上运行。(就是告诉GPU,这个是需要运行在GPU上的函数,但是是来自其他涉笔额 )
GPU的编译器驱动就是NVCC,它调用多个编译器和其他工具想脚本一样编译代码,同时它还可以把代码划分为宿主和设备两部分。host上的代码可能会通过gcc/g++编译。通过__global__定义后 全局函数中的代码编译成可在gpu上运行的形式。
调用核函数 :mykernel函数在GPU上开始执行,还传递了内核启动配置参数1,1
mykernel<<<1,1>>>( );
同时GPU也类似CPU有内存分配复制的函数:
cudaMalloc(), cudaFree(), cudaMemcpy()
这些API利用指针来引用内存空间或者定义内存分配。
需要注意的是CPU memory的指针不要在 device code中解引用,GPU的指针也不要在host code中解引用。
这是两个不同处理器的两个不同memory的分配。
在cuda中,add<<<1,1>>>( )和add<<<N,1>>>( )的意思是不一样的,
这是将内核启动n个块,第二个参数1实际上指的是线程。我们告诉cuda,我们启动了n个块,每个块包含1个线程。所有这些n个块都能够在某个程序上并行执行。线程与块的统称称为gird。
在CUDA中grid的子集是block,一个block代表一个或一组worke(比如一个add( )。
然后一组block称为grid,每个block可以用索引表示blockIdx.x,例如:
__global__ void add(int *a, int *b, int *c) {
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];
}
add参数列表包含三个指针 a,b,c .这三个指针用于引用三个向量A B C。
函数体内,返回类型为void。
blockIdx.x:这是一个内置变量,表示当前线程块在网格中的索引。每个线程块有一个唯一的 blockIdx.x 值。
c[blockIdx.x] = a[blockIdx.x] + b[blockIdx.x];:这行代码表示,对应于 blockIdx.x 的每个线程块执行一个向量加法操作,即将数组 a 和数组 b 中对应位置的元素相加,并将结果存储在数组 c 的相同位置。
而对于host code来说:
#define N 512
int main(void){
int *a,*b,*c; //host cpoies of a,b,c
int *d_a,*d_b,*d_c; //device copies of a,b,c
int size = N * sizeof(int);
//cuda分配空间给d_a ,大小为size void**为指向指针的指针
cudaMalloc((void **) &d_a, size);
cudaMalloc((void**)&d_b,size);
cudaMalloc(void **)&d_c,size;
//在主机内存中分配一个包含N个整数的数组,并将指针存到a中
//用整数随机初始化数组a
a = (int *)malloc(size); random_ints(a,N);
b = (int *)malloc(size); random_ints(b,N);
c = (int *)malloc(size);
//把数据copy到device中
cudaMemcpy(d_a,a,size,cudaMemcpyHostToDevie);
cudaMemcpy(d_b,b,size,cudaMemcpyHostToDevie);
//启动add()kernel在GPU上N个blocks
add<<<N,1>>>(d_a,d_b,d_c);
//把计算的数据写回到host
cudaMemcpy(c,d_c,size,cudaMemcpyDeviceToHost);
//释放
free(a); free(b); free(c);
cudaFree(d _a);cudaFree(d_b);cuda_Free(d_c);
;}
了解了这些,我们对cuda有了个宏观的概念,最大的是grid,其次是block,在最后是thread。thread存在于工作层次的最底层。所以我们可以把代码修改为:
__global__ void add(int *a, int *b, int *c) {
c[threadIdx.x] = a[threadIdx.x] + b[threadIdx.x];
}
但是想要激发thread的并行性,我们必须要修改内核启动参数的第二个数字add<<<1,N>>>( );
所以综合上述两个例子,我们第一次使用了单线程的N个block和1个block的N个线程来进行并行向量加法。
如果同时使用N个线程N个block呢?
在这之前我们先看下数据索引
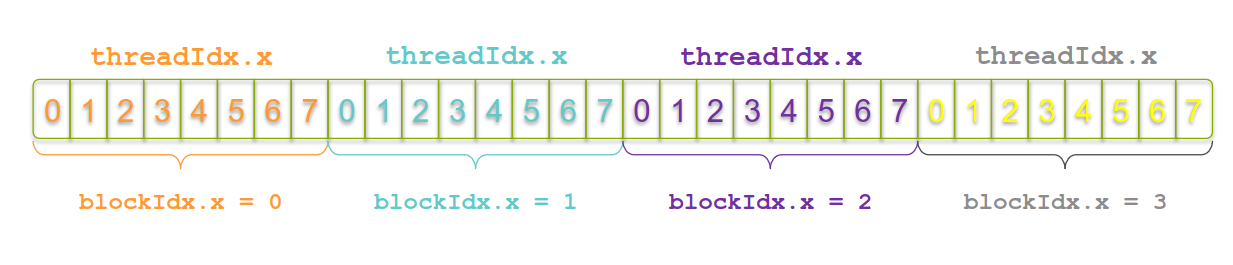
可以看到每个block都是唯一的,但是thread却不是唯一的,在每个block中都有thread。所以这些无法满足全局索引。那么为了满足全局索引,
其实这就跟多维数组一样,需要查找的时候要用全局索引,所以同多维数组的索引值:
int index = threadIdx.x + blockIdx.x * blockDim.x;
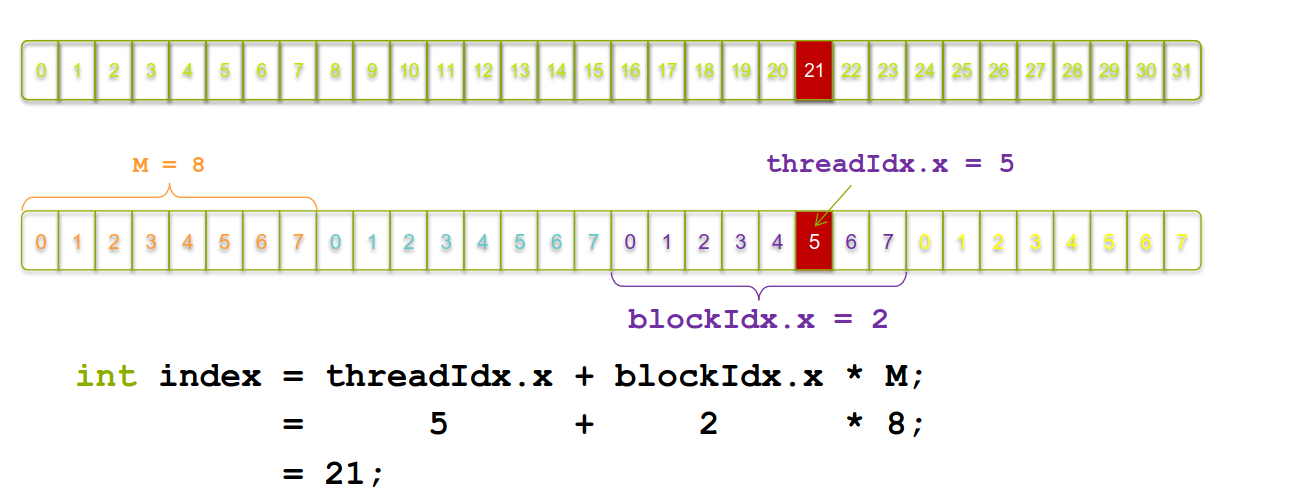
如果面对多维呢
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
int main(void) {
int *a, *b, *c; // host copies of a, b, c
int *d_a, *d_b, *d_c; // device copies of a, b, c
int size = N * sizeof(int);
// Alloc space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Alloc space for host copies of a, b, c and setup input values
a = (int *)malloc(size); random_ints(a, N);
b = (int *)malloc(size); random_ints(b, N);
c = (int *)malloc(size);
/ Copy inputs to device
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<N/THREADS_PER_BLOCK,THREADS_PER_BLOCK>>>(d_a, d_b, d_c);
// Copy result back to host
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
// Cleanup
free(a); free(b); free(c);
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
return 0;
}
我们可以看到唯一和一维数组的代码不同的是add<<< >>>中的数字。并行计算了N/512个块,每个块中有512个thread。
同时我们还需处理异常情况,例如溢出:
__global__ void add(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n)
c[index] = a[index] + b[index];
}
这里的索引在计算前先来个if判断防止溢出,确保需要的线程进行运算。
同时还需要更新kernel:
add<<<(N + M-1) / M,M>>>(d_a, d_b, d_c, N);
假设我们有 N 个元素,每个块包含 M 个线程:
(N + M - 1):这是为了确保当 N 不能被 M 整除时,可以正确地计算需要多少个块。通过加上 M - 1,可以向上取整。例如,如果 N = 10 和 M = 4,那么我们需要 3 个块(10 元素分成 3 个块,每块 4 个线程,但最后一个块只有 2 个线程)。
/ M:这是计算总共需要多少个块。将总线程数除以每个块的线程数,就得到了块的数量。
通常情况下会启动超过所需数量的thread,而那些而外的thread由内核代码if进行处理
在cuda中多维线程:
多维网格和多维线程本质还是一维的,GPU物理上不分块。上图就是一个二维的线程,注意第一个block是0,0 第二个block是1,0 第三个block是2,0 第四个block是0,1 这是因为block的变化首先是以x变化的,thread也是同理,都是以x先变化的。不同于普通的矩阵
所以对于二维线程来说:
int tid = threadIdx.y * blockDim.x + threadIdx.x;
int bid = blockIdx.y * gridDim.x + blockIdx.x;
上面两行代码是在二维线程中的全局索引,可以看到结尾都是加上threadIdx.x,这也印证了我们刚才说的 是以x先变化的。
下面是二维网格二维线程块的具体描述

三维网格三维线程块的具体描述 注意blockDim.x都是已经给定的值就是一个block中多少列,blockDim.y就是有多少行,blockDim.z就是有多少层。类似数据结构中计算数组的那个全局索引是类似的。
注意blockDim.x都是已经给定的值就是一个block中多少列,blockDim.y就是有多少行,blockDim.z就是有多少层。类似数据结构中计算数组的那个全局索引是类似的。
所以常见的一维索引如下:
//一维grid 一维block
//blockIdx.x就是在第几个block中 threadIdx.x就是在第几个线程
int blockId = blockIdx.x;
int id = blockIdx.x*blockDim.x + threadIdx.x
//一维grid 二维block
int blockId = blockIdx.x;
//前部分是之前block的总线程数,第二部分是当前block对应的线程数。
int id = blockIdx.x * (blockDim.x * blockDim.y) + threadIdx.x + threadIdx.y*blockDim.x;
//一维grid 三维block
int blockIdx = blockIdx.x;
int id = blockIdx.x * blockDim.x * blockDim.y * blockDim.z + blockDim.x *blockDim.y* threadIdx.z + blockIdx.y * blockDim.x + threadIdx.x;
//二维grid 一维block
int blockid = blockIdx.y * gridDim.x + blockidx.x;
int id = blockid * blockDim.x + threadIdx.x;
//二维grid 二维block
int blockid = blockIdx.y * gridDim.x + blockIdx.x;
int id = blockIdx * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + threadIdx.x;
//三维grid 三维block
int blockid = blockIdx.z * gridDim.x * gridDim.y + blockIdx.y * gridDim.x + blockIdx.x;
int id = blockid * blockDim.x * blockDim.y * blockDim.z + threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x + theadIdx.x;
1、定义核函数:用 global 关键字定义一个核函数。核函数的返回类型必须是 void。
__global__ void kernel_function(int *a, int *b, int *c) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] + b[index];
}
2、调用核函数:在主机代码(host code)中,使用特殊的语法调用核函数,指定执行配置(execution configuration),包括网格(grid)和块(block)的尺寸。
int main() {
int *d_a, *d_b, *d_c;
int size = N * sizeof(int);
// 分配设备内存
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
// 拷贝数据到设备
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 执行核函数
int blocks = (N + threadsPerBlock - 1) / threadsPerBlock;
kernel_function<<<blocks, threadsPerBlock>>>(d_a, d_b, d_c);
// 拷贝结果回主机
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
// 释放设备内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
所以总结成一个模板来说,就可以简单的认为如下流程:
#include
__global_void 函数名(arg...){
***kernel content
}
int main(void){
设置GPU设备
分配host device内存
初始化主机数据
数据从主机复制到设备
调用核函数在设备中进行计算
将计算得到的数据从设备传给主机
释放主机与设备内存
}
这里的矩阵相乘还是在举个例子,但是先举一个CPU的例子!!注意这里是CPU而非并行的GPU
//a00 a01 a02 //b00 b01 b02 b03
//a10 a11 a12 //b10 b11 b12 b13
//b20 b21 b22 b23
// c 2 4
// c00 c01 c02 c03
// c10 c11 c12 c13
其中a矩阵是23 b是34 c是2*4
c[0][0] = a[0][0]*b[0][0]+a[0][1]*b[1][0]+a[0][2]*b[2][0];
c[0][1] = a[0][0]*b[0][1]+a[0][1]*b[1][1]+a[0][2]b[2][1];
而在计算机中多维矩阵是按一维数组的方式存储的,所以a和b有不同的索引表示:
a_index = y * size + step;
b_index = step * size + x;
size就是3 也就是矩阵相乘时维度相同的那个值。
所以c[0][1]就是 y = 0,step=0,1,2 x=1时相乘得到的
所以a和b都是行优先存储后,在机内表示如下:
a00 a01 a02 | a10 a11 a12
b00 b01 b02 b03 | b10 b11 b12 b13| b20 b21 b22 b23
所以矩阵相乘时,每次相乘都需要把b的索引+一个step,由于ab最后输出矩阵是24,所以具体的矩阵相乘代码如下:
假设a(2,3) h=2,k=3
b(3,4) w = 4
for(int y = 0;y < 2; y++){
for(int x = 0;x < 4; x++){
int res = 0;
//计算输出矩阵c,a和b相乘,z就是维度中间相同的那个2*3 3*4
for(int z = 0;z < k;z ++){
res += a[y*k+z]*b[z * w + x];
}
c[y * w + x] = res;
}
}
清楚了CPU的例子后我们再来举例GPU的例子。
__global__ void simple_matmul_k(float* m, float* n, float* out, int h, int w, int k) {
int y = blockIdx.y*blockDim.y + threadIdx.y;
int x = blockIdx.x*blockDim.x + threadIdx.x;
if (y>=h || x>=w) return;
float o = 0;
for (int i = 0; i<k; ++i) o += m[y*k+i] * n[i*w+x];
out[r*w+c] = o;
}

欢迎来到FlagOS开发社区,这里是一个汇聚了AI开发者、数据科学家、机器学习爱好者以及业界专家的活力平台。我们致力于成为业内领先的Triton技术交流与应用分享的殿堂,为推动人工智能技术的普及与深化应用贡献力量。
更多推荐

 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)